
Neural Networks

What is a neural network?
A Neural Network is a system inspired by the human brain that is designed to recognize patterns. Simply put it is a mathematical function that maps a given input in conjunction with information from other nodes to develop an output.
What can a neural network do?
Neural Networks have a wide range of real-world and industrial applications a few examples are:
Guidance systems for self-driving cars
Customer behavior modeling in business analytics
Adaptive learning software for education
Facial recognition technology
And that’s just scratching the surface.
How does a neural network work?

A simple neural network includes an input layer, an output layer, and, in between, a hidden layer.
Input layer- this is where data is fed and passed to the next layer
Hidden layer- this does all kinds of calculations and feature extractions described below
Output layer- this delivers the final result
Each layer is connected via nodes. The nodes are activated when data is fed to the input layer. It is then passed to the hidden layer where processing and calculations take place through a system of weighted connections. Finally, the hidden layers link to the output layer — where the outputs are retrieved.
What python libraries or packages can you use?
There are a variety of useful python libraries that can be used ;
Pytorch- Apart from Python, PyTorch also has support for C++ with its C++ interface if you’re into that.
Keras- is one of the most popular and open-source neural network libraries for Python.
Tensorflow- is one of the best libraries available for working with Machine Learning on Python
Scikit-learn- It includes easy integration with different ML programming libraries like NumPy and Pandas
Theano- is a powerful Python library enabling easy defining, optimizing, and evaluation of powerful mathematical expressions
Numpy- concentrates on handling extensive multi-dimensional data and the intricate mathematical functions operating on the data.
Pandas- is a Python data analysis library and is used primarily for data manipulation and analysis.
How to implement a single-layer neural network in basic python to solve an XOR logic problem?
The Python language can be used to build neural networks from simple ones to the most complex. In this tutorial, you will learn how to solve an XOR logic problem. XOR problem is a valuable challenge because it is the simplest linearly inseparable problem that exists. It is a classic problem that helps in understanding the basics of Deep Learning. XOR (Exclusive OR) compares two input bits and generates one output bit; in other words, you must have one or the other but not both. The table below represents what we will implement in the code.

To begin we will use the python library NumPy which provides great functions and simplifies calculations. You can follow along in this linked Jupyter Notebook, or in your favorite text editor to begin by defining parameters.

Next is to define the weights and biases between each layer. Weights and biases are the learnable parameters of neural networks and other machine learning models. Weights determine how much influence the input has on the output. Biases that are constant have no incoming connections but have outgoing connections with their own weights. Biases guarantee activation even when inputs are zero. In this case, I did not use a bias. The weights have been set to random values.

I will then create functions for the activation of the neuron. Here we use the Sigmoid function which is normally used when the model is predicting probability. After activation forward propagation begins, this is the calculation for the predicted output. After we have calculated the output activations they will be returned to be used in further calculations. All values calculated during forward propagation are stored as they will be required during backpropagation. Backpropagation is the trial and error method of learning our neural network uses. It determines how much we should adjust the weights to improve the accuracy of our predictions.

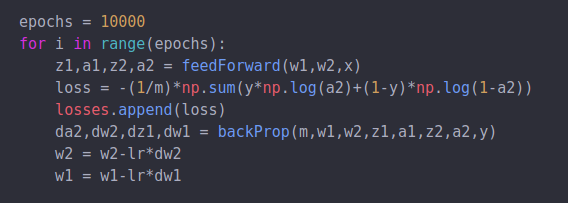
In the end, we run the neural network for 10000 EPOCHS and view the loss function. An Epoch is when training neural networks the training data is used for one cycle the data is passed both forward and backward. A Forward pass and a backward pass are counted as one. In an Epoch the data is used just once. A loss function quantifies the difference between the expected outcome and the outcome produced by the neural network.
Following are the predictions of the neural network on test inputs:


We know that for XOR inputs 1,0 and 0,1 will give output 1 and inputs 1,1 and 0,0 will output 0. Another way to go about replicating this experiment is by using Tensorflow see it differs from NumPy in one major respect: TensorFlow is designed for use in machine learning and AI applications and so has libraries and functions designed for those applications. Pytorch is also great because it has a decent order over the Graphics Processing Unit it will be very useful in visualizing data to get additional insights into your work. In conclusion, writing the code and experimenting with the various ways to make this neural network will strengthen your skills and boost your knowledge of the inner workings of neural networks.
You can stay up to date with Accel.AI; workshops, research, and social impact initiatives through our website, mailing list, meetup group, Twitter, and Facebook.